Programming Challenges - 3n + 1 Problem
Arne Olav Hallingstad14th November 2010
Home
Introduction
The Programming Challenges book got a lot of interesting programming challenges that's intended to be solved in ANSI C, C++, Java or Pascal. The 3n + 1 problem is basically the first challenge in the book and this article describes the various programs I created to solve a certain data set in the least amount of time.
The general 3n + 1 problem is also known as the 3n + 1 conjecture or Collatz conjecture, an unsolved conjecture in mathematics!
Initial Implementation
Since I'm a C/C++ programmer all my implementations were a mix between these languages. The first attempt would be the naive and straight forward one:
#include < stdio.h >
#pragma warning( disable: 4996 )
#pragma warning( error: 4717 )
template< class T > T Max( T a, T b ) { return a > b ? a : b; }
template< class T > void SwapValues( T& a, T& b ) { T temp( a ); a = b; b = temp; }
int SequenceLength( unsigned int val ) {
if ( val == 1 ) {
return 1;
}
val = val % 2 != 0 ? val * 3 + 1 : val / 2;
return SequenceLength( val ) + 1;
}
int Process( int start, int end ) {
int bestLength = 0;
for ( int i = start; i <= end; i++ ) {
bestLength = Max( bestLength, SequenceLength( i ) );
}
return bestLength;
}
int main( int argc, char* argv[] ) {
while ( true ) {
int start, end;
bool eof = scanf( "%i %i", &start;, &end; ) == EOF;
if ( eof ) {
break;
}
if ( start > end ) {
int maxCycle = Process( end, start );
printf( "%i %i %i\n", start, end, maxCycle );
} else {
int maxCycle = Process( start, end );
printf( "%i %i %i\n", start, end, maxCycle );
}
}
return 0;
}
The program was submitted at the Programming Challenges website where automated scripts ran the program on their data set. It solved the problem in 0.752 seconds which seemed like a reasonable start.
Feasibility - Generating Table With One Million Entries
Looking at ways to improve the timings, since the problem states that SequenceLength() will be calculating the sequence length for each value from zero to one million, an obvious improvement would be to cache the result of this calculation for all one million numbers. Basically a table lookup, thinking about this there's quite a few obstacles to overcome.
- The table with a million numbers will take up 4MB, assuming its stored as binary data and each value is a 4-byte integer!
- We don't know the range of all possible values, if we did we could limit the storage size to shorts or even bytes, decreasing the size.
- The table must be part of the source file being uploaded to Programming Challenges. We are not allowed to do a binary open on a file which could contain the table, this complicates things.
Since the table must be stored in the source code I created a program that spits out a table we can copy and paste in:
int maxCycle[] = {
1,2,8,3,6,9,17,4,20,7,15,10,10,18,18,5,13,21,21,....
}
That's one million entries. It pretty much froze my Visual Studio Editor as it couldn't cope with text files of ~3.6MB. Each value took up an average of 3.6 bytes. This number needed to go down drastically for a table lookup to be feasible. From submitting source file of varying sizes I found that anything below ~2MB would not fail to be uploaded.
For testing if it was possible to solve at all by using a table lookup, I looked at the best compression I could use, zip compressing the source code took the size down to 500KB. Uploading a program that uses table lookup while solving the problem will be possible.
Finding the Range
I started looking at ways to reduce the size of the table from the initial 3.6MB down below 2MB. First of all I wanted to know what ranges all the values were in so I could reduce the storage size from an integer. I created a program that generates a file with CSV of how many times each value in the table was used, the histogram looked like this:
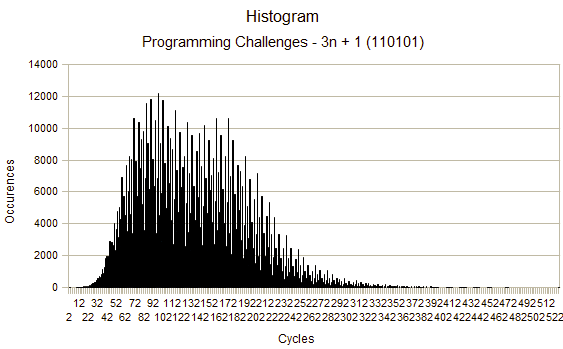
The majority of the values were in the 0 to 255 range which meant we would only need one byte to represent its values, and a few table values were in the 256 to 512 range. All values could be represented with a short, while ~95% could be represented with a byte.
Sharp minds would see from the maxCycle table above that it makes no difference what storage type we use if it's being stored as text in the source file. It will be stored with 3.6 bytes per value, including the comma between each entry. That's a lot of wasted space when strictly speaking we only need slightly more than 1 byte per value could we have stored it as binary and not text.
Base64 Encoded Data
To be able to reduce the size of the table, we must store it as binary data, which we can't directly do as it must be part of the source file to be able to be submitted to the jury bot on the Programming Challenges web site.
We can store it in a null-terminated string which we reinterpret as the table array. There's two issues we need to solve if we are to store the table in a string:
- The Visual C++ compiler (GCC as well? this might be in the standard) only permits string literals to be less than 65 535 bytes. That's a problem if you got a 2 000 000 byte null terminated string (when using a short storage type for the table values).
- Since it's not proper ASCII text it will be unsafe to store the data directly as text since it could and probably will contain escape characters which will make the compile fail.
We'll have to encode the data in a format which contains only valid ASCII characters. This is what Base64 encoding does and is commonly used to transfer binary data in HTTP requests. Base64 encoding takes 3 bytes of data and encodes it with 4 bytes of ASCII characters, this means the size will increase by 33.33%, which is unfortunate but it seems unavoidable I think. Read more about Base64 encoding on Wikipedia
It also means at runtime we must decode this Base64 string into data, generating 3 bytes of data for every 4 ASCII characters. Time will tell if this extra step is too time consuming compared to the initial implementation.
Avoiding 65535 Literal String Length Limit of Compiler
Now that we've got a way of representing the binary data in the source code the next step was to make sure the data could be included in the source file without compiler errors.
I made a program that would output all the Base64 encoded data into a series of strings of length 65535 and a table that would point to these strings in order. That way when the program is loaded it can reconstruct the original string on the heap from these fragments. The strings and array generated would look something like this:
const char* tableData1 = "AEgAIMgBJEBBUcwDKogESUQDVUBC..."
const char* tableData2 = "Q+aGmQGZzMzMSlxrZIFkQCJZzkRG..."
const char* tableData3 = "iEkIBBGYg12Ui83fTNlneOVOT55q..."
int tableDataSize[] = {
65534,
65534,
35600,
};
int tableDataStringTotalSize = 166668;
const char* tableDataTable[] = {
tableData1,
tableData2,
tableData3,
};
To reconstruct the original Base64 string I created a function ReadAlloc:
char* base64DataStream = ReadAlloc( dataDataTable, sizeof( dataDataTable ) / sizeof( dataDataTable[ 0 ] ), dataDataSize, dataDataStringTotalSize );
With the definition:
char* ReadAlloc( const char* table[], int num, const int* tableSizes, const int totalSize ) {
char* dataString = new char[ totalSize ];
int offset = 0;
for ( int i = 0; i < num; i++ ) {
memcpy( dataString + offset, table[ i ], sizeof( char ) * tableSizes[ i ] );
offset += tableSizes[ i ];
}
return dataString;
}
Huffman Compression
Base64 encoding the whole string so it could be included in the source code increased the size from 2MB to about 2.66MB. I therefore implemented Huffman Compression so that the max cycle values could be represented as efficiently as possible. Huffman coding generates a binary tree where the values which occur the most is represented with the fewest number of bits.
The program would have to decode the Base64 string then decode the Huffman encoding before we could actually start solving the data set. This was how the code looked so far:
byte* huffCode; int huffCodeSize; byte* huffData; DecodeBase64Huffman( huffCode64DataTable, sizeof( huffCode64DataTable ) / sizeof( huffCode64DataTable[ 0 ] ), huffCode64DataSize, huffCode64DataStringTotalSize, huffData64DataTable, sizeof( huffData64DataTable ) / sizeof( huffData64DataTable[ 0 ] ), huffData64DataSize, huffData64DataStringTotalSize, huffCode, huffCodeSize, huffData ); int* decompressedMaxCycles; aoHuffmanCompression huffman; huffman.Decompress( huffCode, huffCodeSize, huffData, MAX_SIZE, decompressedMaxCycles ); // Use decompressedMaxCycles to solve the data set
This reduced the size of the Base64 encoded table from 2.66MB to 1.45MB which gives a 54.5% compression ratio.
Base64 and Huffman Encoder - What's Next?
To improve compression even further huffman encoding is often paired with delta compression because a lot of the same values occur after each other. Before seeing if this is something we need to consider there were a few things to note:
- We're doing Base64 and Huffman decoding at runtime which might be too slow already.
- The source file is ~1.5MB which is within the allowed limits of the referee bot we are submitting the source code to.
Submitting the source code to the referee bot at Programming Challenges it solved the problem in 0.104 seconds which is only 13.8% of the time spent in the original implementation.
Considering this we do not want to add additional compression, but perhaps look for simpler solutions, huffman encoding is fairly CPU intensive.
Simplifying the Compression
Through tests it seemed that a lot of time was spent decoding the huffman encoding. Another approach I thought of instead of using huffman encoding is that we could use two streams of Base64 data.
The first bit stream is a stream with one bit per table entry signifying if it was stored as a byte or short. The second bit stream is the data stream which contains a list of either bytes or shorts, one for each table entry.
Doing this we really simplify the complex huffman coding. It's traversing two streams and copying either one or two bytes from the data stream per table entry based on the value of each bit in the first bit stream:
char* base64BitStream = ReadAlloc(
tableDataTable,
sizeof( tableDataTable ) / sizeof( tableDataTable[ 0 ] ),
tableDataSize,
tableDataStringTotalSize );
char* base64DataStream = ReadAlloc(
dataDataTable,
sizeof( dataDataTable ) / sizeof( dataDataTable[ 0 ] ),
dataDataSize,
dataDataStringTotalSize );
// decode from base64
byte* bitStream = NULL;
byte* dataStream = NULL;
unsigned int bitStreamSize, dataStreamSize;
aoBase64Encoder encoder;
encoder.DecodeAlloc( base64BitStream, tableDataStringTotalSize, bitStream, bitStreamSize );
encoder.DecodeAlloc( base64DataStream, dataDataStringTotalSize, dataStream, dataStreamSize );
byte* bitStreamPtr = bitStream;
byte* dataStreamPtr = dataStream;
int curBit = 0;
for ( int i = 0; i < MAX_SIZE + 1; i++ ) {
// short
if ( (*bitStreamPtr) & ( 1 << curBit ) ) {
maxCycles[ i ] = *(unsigned short*)dataStreamPtr;
dataStreamPtr += 2;
} else {
// byte
maxCycles[ i ] = *dataStreamPtr++;
}
AdvanceCurBit( bitStreamPtr, curBit, 1 );
}
// use maxCycles to solve the data set
The new source file size was 1.55MB which is almost as good as the huffman encoded version. The good compression comes from storing the majority of the entries as bytes.
Running the program on the data set again it was solved in 0.052 seconds. That's only 6.9% of the time spent in the original implementation and 50% of the time spent in the program which used the huffman compression.
Another Approach - Lazy Table Lookup
Another approach which is less complex was the use of lazy table lookup. The table isn't pre-generated, but populated with values as it is being looked up at runtime. Any subsequent lookups for the same values can look up the values from the table:
#include < stdio.h >
#include < assert.h >
#pragma warning( disable: 4996 )
#pragma warning( error: 4717 )
template< class T > T Max( T a, T b ) { return a > b ? a : b; }
template< class T > void SwapValues( T& a, T& b ) { T temp( a ); a = b; b = temp; }
static const int MAX_SIZE = 100000001;
static unsigned short cycle[ MAX_SIZE ];
unsigned short SequenceLength( unsigned int val ) {
if ( val < MAX_SIZE && cycle[ val ] != 0 ) {
return cycle[ val ];
}
val = val % 2 != 0 ? (((val << 1) | 1) + val ) : val / 2;
return SequenceLength( val ) + 1;
}
unsigned short Process( int start, int end ) {
unsigned short bestLength = 0;
for ( int i = start; i <= end; i++ ) {
if ( cycle[ i ] == 0 ) {
cycle[ i ] = SequenceLength( i );
}
bestLength = Max( bestLength, cycle[ i ] );
}
return bestLength;
}
int main( int argc, char* argv[] ) {
cycle[ 1 ] = 1;
while ( true ) {
int start, end;
bool eof = scanf( "%i %i", &start;, &end; ) == EOF;
if ( eof ) {
break;
}
if ( start > end ) {
unsigned short maxCycle = Process( end, start );
printf( "%i %i %i\n", start, end, maxCycle );
} else {
unsigned short maxCycle = Process( start, end );
printf( "%i %i %i\n", start, end, maxCycle );
}
}
return 0;
}
This program solved the data set in 0.048 seconds, 4 milliseconds faster than the 1.5MB source file above.
Conclusion
Often in programming it seems the best solution is the simplest solution.
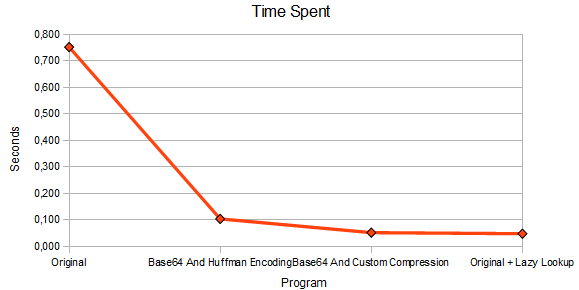
Lazy table lookup, which is a minor change to the original implementation solved the problem in 6.4% of the original time.
